Linux命令行下性能分析
本文最后更新于:2023年12月17日 下午
性能分析
我根据我这些年的经验,挑选了四个“高性价比”的工具:top、pstack、strace 和 perf。它们用起来很简单,而且实用性很强,可以观测到程序的很多外部参数和内部函数调用,由内而外、由表及里地分析程序性能。
top
参数解释
通过top命令,就能够简单直观地看到 应用程序的CPU、内存等几个最关键的性能指标。下面这张图截自ubuntu20.04 虚拟机的top命令。
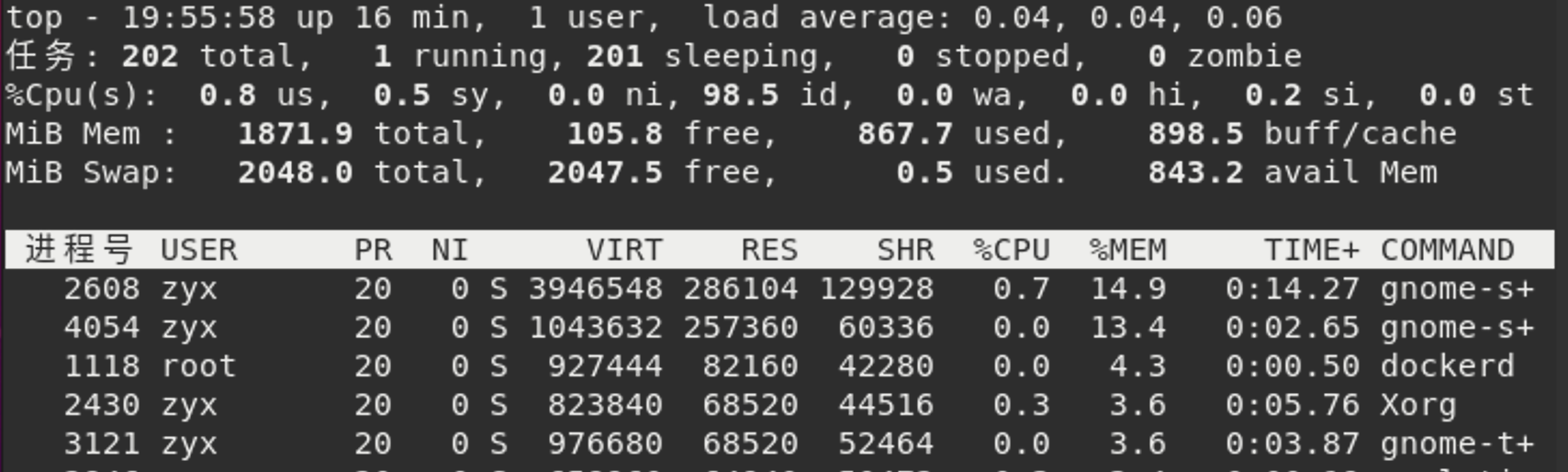
其中个指标的含义可以参考自这篇博客top命令的用法 [1]:
Tasks一行:
total : 进程总数
Running: 正在运行进程数
Sleeping: 睡眠的进程数
Stopped: 停止的进程数
zombie: 僵尸进程数
Cpu一行:
- us:用户空间占用CPU的百分比
- sy:内核空间占用CPU的百分比
- ni:用户进程空间内改变过优先级的进程占用CPU百分比
- id:空闲CPU百分比
- wa:等待输入输出的CPU百分比
- hi:硬中断占用CPU百分比
- si:软中断占用CPU百分比
- st:当hypervisor服务另一个虚拟处理器的时候,虚拟CPU等待实际CPU的百分比
软中断是执行中断指令产生的,而硬中断是由外设引发的。
为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断来完成。
- Mem为物理内存使用,Swap为交换区使用。
- 白色标注行:
PID:进程ID
USER:进程所有者的用户ID
PR:priority,动态优先级,取值范围[0,99],取值越小,优先级越高。priority的值在之前内核的O1调度器上表现是会变化的,所以叫做动态优先级。
NI:nice值,静态优先级。取值范围[-20,19],取值越小,优先级越高。nice值设定好后,一般是不会改变的,除非使用系统调用进行修改,所以称为静态优先级。
VIRT:进程使用的虚拟内存的总量,VIRT = SWAP + RES
RES:进程使用的、未被换出的物理内存大小,单位kb,RES = CODE + DATA
SHR:共享内存,也会被统计在RES中。
除了自身进程的共享内存,也包括其他进程的共享内存;
虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小;
计算某个进程所占的物理内存大小公式:RES – SHR;
S:进程状态
- R:当前正在运行(RUNNING)
- S:睡眠(SLEEP)
- D:不可中断
- T:停止(STOP)
- Z:僵尸进程(ZOMBIE)
%CPU:上次更新到现在的CPU时间占用百分比
%MEM:进程占用物理内存占比
TIME+:进程使用CPU时间总结
COMMAND:进程名称(命名名/命令行)

交互命令
- 按
f键进入交互界面,此时按d可以显示或隐藏列,按s可以设置当前选中的列进行排序,默认为降序,可以按R进行升序(注意大写)。

- 先按
->右键表示选中该列,在按上下移动键,就可以调整列的显示顺序

- h或者 **?**:显示帮助画面
- k :终止一个进程;默认使用15信号,可以使用信号9来强制结束该进程。但是在安全模式下此命令被屏蔽。
- t :切换显示进程和CPU状态信息。
- m :切换显示内存信息。
- H:切换为线程查看模式
- i :忽略闲置和僵死进程,开关式命令。
- M :根据驻留内存大小进行排序。
- P :根据CPU使用百分比大小进行排序。
- T :根据时间或者累计时间进行排序。
- top -d 秒数:表示进程界面更新时间(默认5秒)
- top -p 1 : 查看进程号为1的进程
pstack
从 top 的输出结果里,我们可以看到进程运行的概况,知道 CPU、内存的使用率。如果发现某个指标超出了预期,就说明程序可能存在问题,接下来,我们就应该采取更具体的措施去进一步分析,比如采用pstack。pstack 可以打印出进程的调用栈信息,有点像是给正在运行的进程拍了个快照,能看到某个时刻的进程里调用的函数和关系,对进程的运行有个初步的印象。
pstack其实是个Shell脚本,核心原理是GDB的thread apply all bt命令,基本逻辑是通过进程号process-id来分析是否使用了多线程,同时使用GDB Attach到在跑进程上,最后调用bt子命令后简单格式化输出[2]。
编写一个测试程序如下,创建一个死循环线程,不停地睡眠1秒后输出。
1 | |
编译命令:g++ -g -pthread test2.cpp -o test2。
pstack命令:sudo pstack ${pid}这里的pid可通过top或者ps来找到。注意这里不加sudo可能不会打印输出。
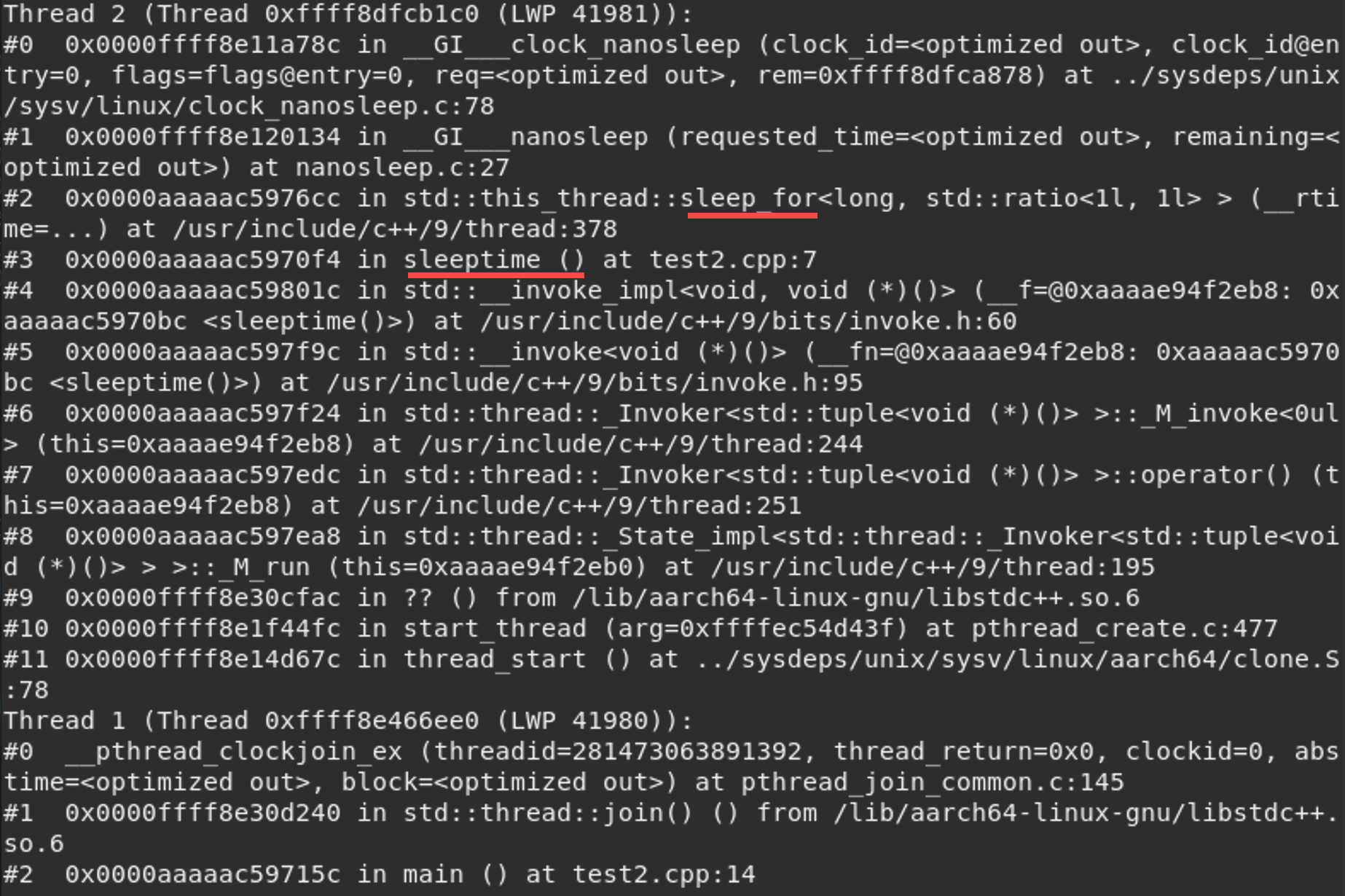
strace
strace是个功能强大的Linux调试分析诊断工具,可用于跟踪程序执行时进程系统调用(system call)和所接收的信号,尤其是针对源码不可读或源码无法再编译的程序。在Linux系统中,用户进程不能直接访问计算机硬件设备。当进程需要访问硬件设备(如读取磁盘文件或接收网络数据等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可跟踪进程产生的系统调用,包括参数、返回值和执行所消耗的时间。[3]
参考知乎这篇文章Linux进程照妖镜strace命令,演示下 strace 命令作用。
首先编写一个测试程序,如下所示:
1 | |
然后执行下列命令:
1 | |
就可以看到程序产生的系统调用:
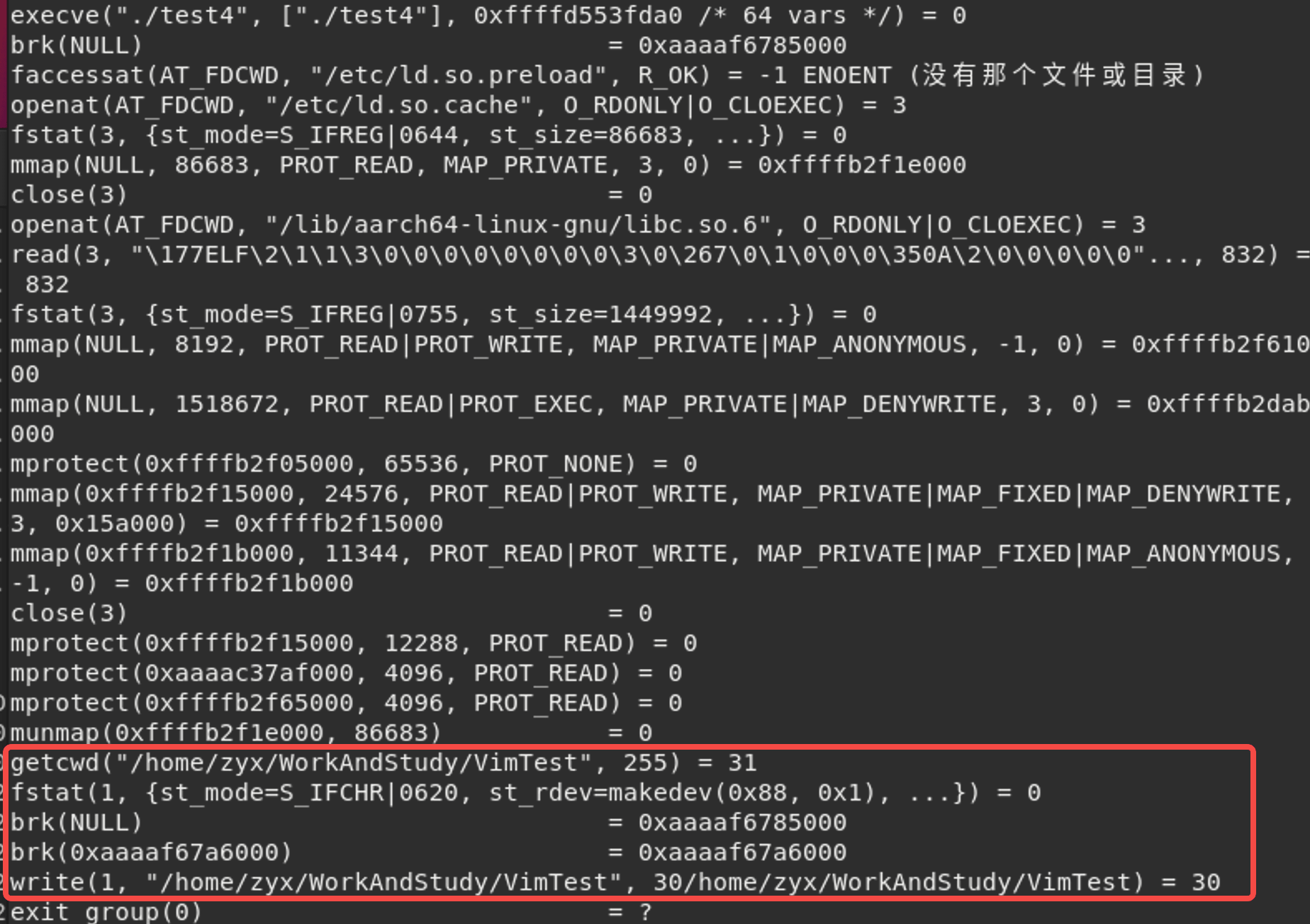
根据上述那片知乎文章参考,可以看到这里程序调用了getcwd函数,获取当前工作目录的绝对路径;fstat是用于检查文件状态,brk系统调用查阅了一下,大致作用是请求内核允许读写一个称为堆的连续内存块[4],或者是说用于进程的内存分配[5];write则是往文件写入内容。
strace的常用命令:
1 | |
把 pstack 和 strace 结合起来,我们大概就可以知道,进程在用户空间和内核空间都干了些什么。当进程的 CPU 利用率过高或者过低的时候,我们有很大概率能直接发现瓶颈所在。
perf
perf 可以说是 pstack 和 strace 的“高级版”,它按照固定的频率去“采样”,相当于连续执行多次的 pstack,然后再统计函数的调用次数,算出百分比。只要采样的频率足够大,把这些“瞬时截面”组合在一起,就可以得到进程运行时的可信数据,比较全面地描述出程序的运行情况。
首先执行下面命令,安装perf:
1 | |
但是提示我需要再安装新的包,这里我再安装linux-tools-5.4.0-97-generic就可以了。

或者直接安装所有相关的依赖包:
1 | |
然后执行 sudo perf top命令,就可以看到 perf界面,如下图所示:
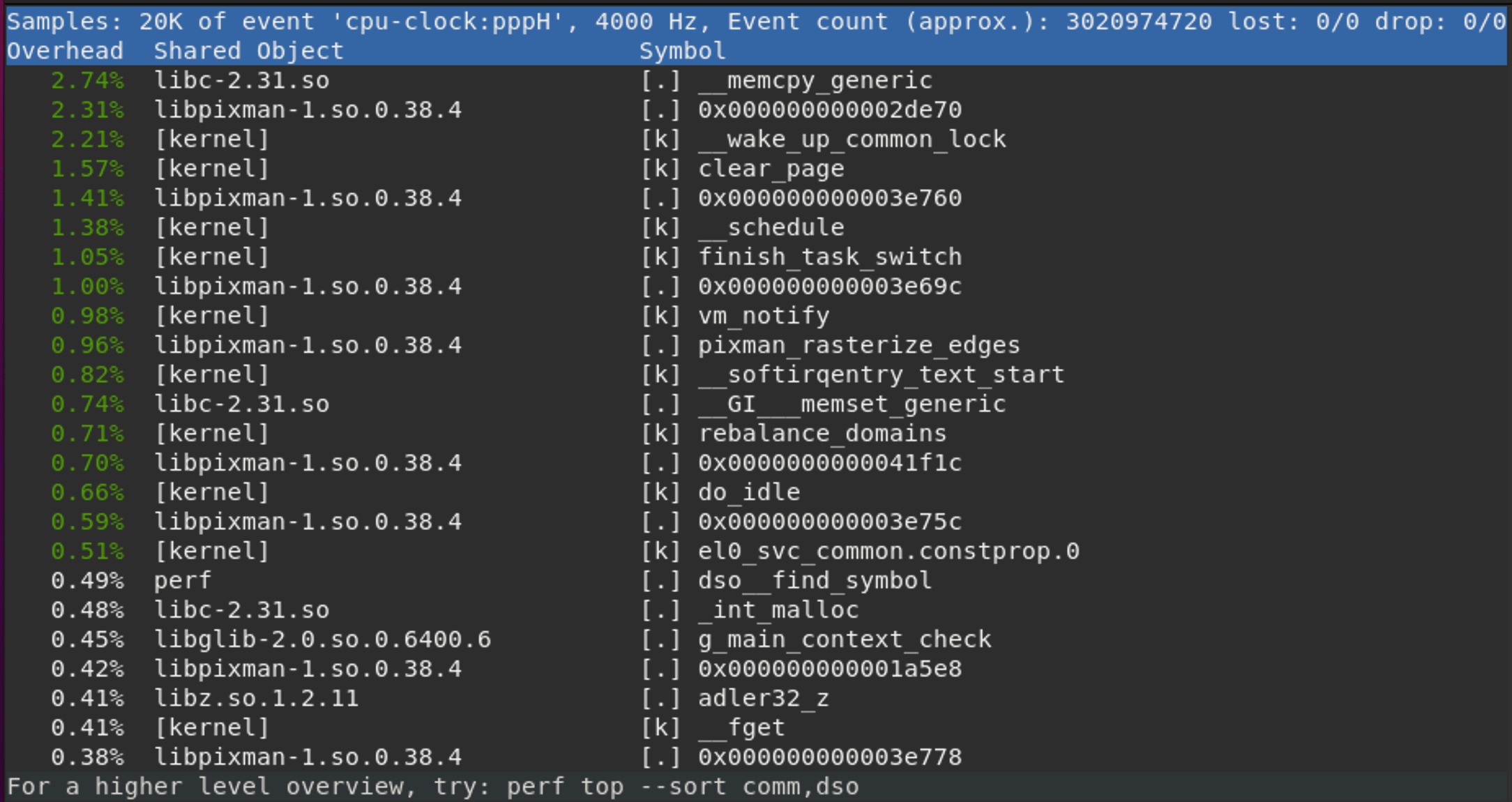
参考这篇文章系统级性能分析工具perf的介绍与使用,了解各列的含义:
第一列:符号引发的性能事件的比例,指占用的cpu周期比例。
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库;[k]表述此符号属于内核或模块。
第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
perf top常用选项有:
-e < event >:指明要分析的性能事件。
-p < pid >:Profile events on existing Process ID (comma sperated list). 仅分析目标进程及其创建的线程。
-k < path >:Path to vmlinux. Required for annotation functionality. 带符号表的内核映像所在的路径。
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d < n >:界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据。
-g:得到函数的调用关系图。
常用的 perf 命令是perf top -K -p xxx,按 CPU 使用率排序,只看用户空间的调用,这样很容易就能找出最耗费 CPU 的程序。
此外,perf 和性能分析中的火焰图也是密切相关,通过perf record采集数据,再通过 FlameGraph 相关命令就可以生成火焰图.
1 | |